
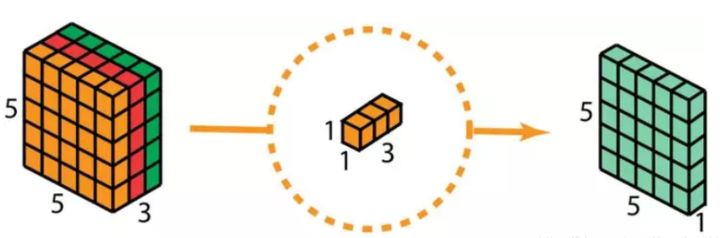
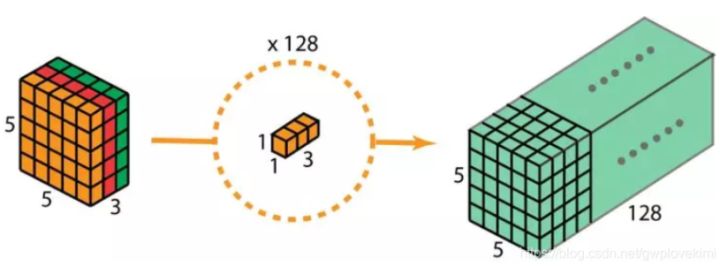
这样的话,做 128 次 1x1 卷积后,就可以得出一个大小为 5 x 5 x 128 的层。
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。
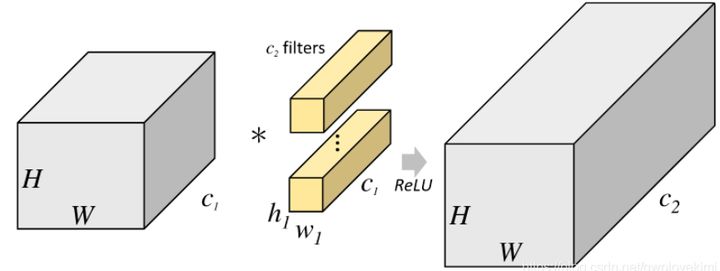
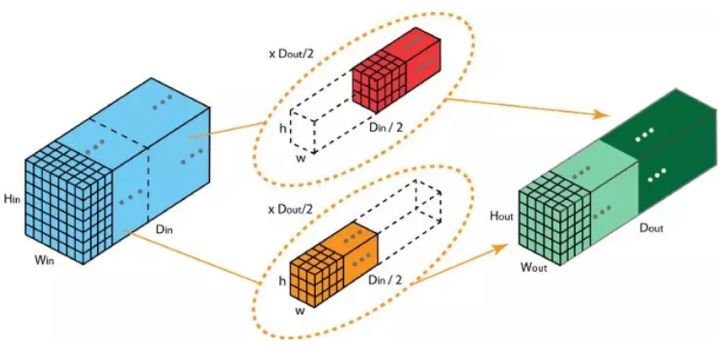
下面描述分组卷积是如何实现的。首先,传统的 2D 卷积步骤如下图所示。在这个案例中,通过应用 128 个过滤器(每个过滤器的大小为 3 x 3 x 3),大小为 7 x 7 x 3 的输入层被转换为大小为 5 x 5 x 128 的输出层。针对通用情况,可概括为:通过应用 Dout 个卷积核(每个卷积核的大小为 h x w x Din),可将大小为 Hin x Win x Din 的输入层转换为大小为 Hout x Wout x Dout 的输出层。在分组卷积中,过滤器被拆分为不同的组,每一个组都负责具有一定深度的传统 2D 卷积的工作。下图的案例表示得更清晰一些。
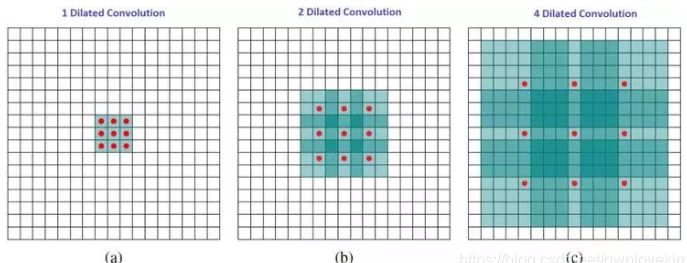
扩张卷积引入另一个卷积层的参数被称为扩张率。这定义了内核中值之间的间距。扩张速率为2的3x3内核将具有与5x5内核相同的视野,而只使用9个参数。 想象一下,使用5x5内核并删除每个间隔的行和列。(如下图所示)系统能以相同的计算成本,提供更大的感受野。扩张卷积在实时分割领域特别受欢迎。 在需要更大的观察范围,且无法承受多个卷积或更大的内核,可以才用它。
直观上,空洞卷积通过在卷积核部分之间插入空间让卷积核「膨胀」。这个增加的参数 l(空洞率)表明了我们想要将卷积核放宽到多大。下图显示了当 l=1,2,4 时的卷积核大小。(当l=1时,空洞卷积就变成了一个标准的卷积)。
这里提到的反卷积跟1维信号处理的反卷积计算是很不一样的,FCN作者称为backwards convolution,有人称Deconvolution layer is a very unfortunate name and should rather be called a transposed convolutional layer. 我们可以知道,在CNN中有con layer与pool layer,con layer进行对图像卷积提取特征,pool layer对图像缩小一半筛选重要特征,对于经典的图像识别CNN网络,如IMAGENET,最后输出结果是1X1X1000,1000是类别种类,1x1得到的是。FCN作者,或者后来对end to end研究的人员,就是对最终1x1的结果使用反卷积(事实上FCN作者最后的输出不是1X1,是图片大小的32分之一,但不影响反卷积的使用)。这里图像的反卷积与图6的full卷积原理是一样的,使用了这一种反卷积手段使得图像可以变大,FCN作者使用的方法是这里所说反卷积的一种变体,这样就可以获得相应的像素值,图像可以实现end to end。