
摘要:在卷积神经网络中,通过使用filters提取不同的特征,这些filters的权重是在训练期间自动学习的,然后将所有这些提取的特征“组合”以做出决策。
本文分享自华为云社区《神经网络常用卷积总结》,原文作者:fdafad 。
进行卷积的目的是从输入中提取有用的特征。在图像处理中,可以选择各种各样的filters。每种类型的filter都有助于从输入图像中提取不同的特征,例如水平/垂直/对角线边缘等特征。在卷积神经网络中,通过使用filters提取不同的特征,这些filters的权重是在训练期间自动学习的,然后将所有这些提取的特征“组合”以做出决策。
目录:2D卷积
3D卷积
1*1卷积
空间可分离卷积
深度可分离卷积
分组卷据
扩展卷积
反卷积
Involution
2D卷积单通道:在深度学习中,卷积本质上是对信号按元素相乘累加得到卷积值。对于具有1个通道的图像,下图演示了卷积的运算形式:
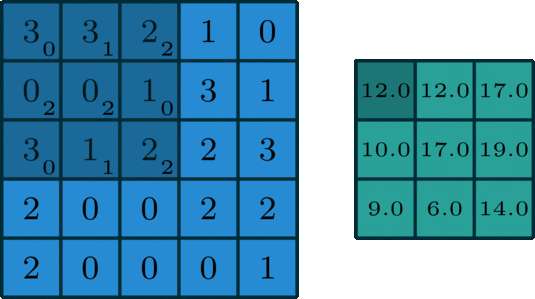
这里的filter是一个3 x 3的矩阵,元素为[[0,1,2],[2,2,0],[0,1,2]]。filter在输入数据中滑动。在每个位置,它都在进行逐元素的乘法和加法。每个滑动位置以一个数字结尾,最终输出为3 x 3矩阵。
多通道:由于图像一般具有RGB3个通道,所以卷积一般多用于多通道输入的场景。下图演示了多通道输入场景的运算形式:
这里输入层是一个5 x 5 x 3矩阵,有3个通道,filters是3 x 3 x 3矩阵。首先,filters中的每个kernels分别应用于输入层中的三个通道,执行三次卷积,产生3个尺寸为3×3的通道:
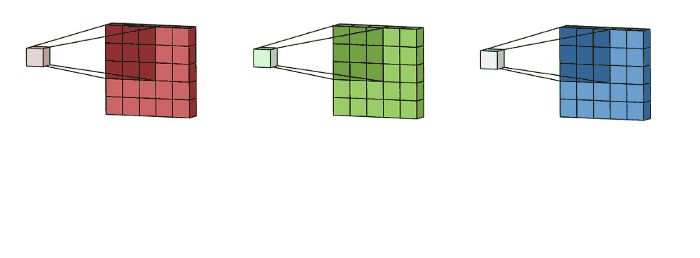
然后将这三个通道相加(逐个元素相加)以形成一个单个通道(3 x 3 x 1),该通道是使用filters(3 x 3 x 3矩阵)对输入层(5 x 5 x 3矩阵)进行卷积的结果:
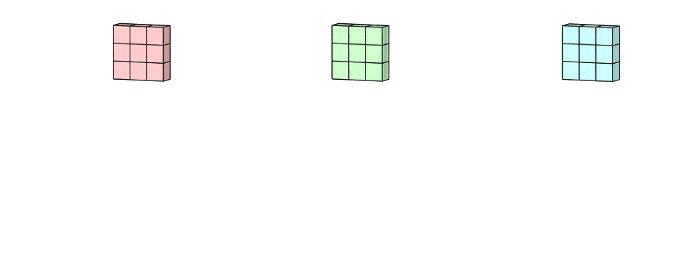
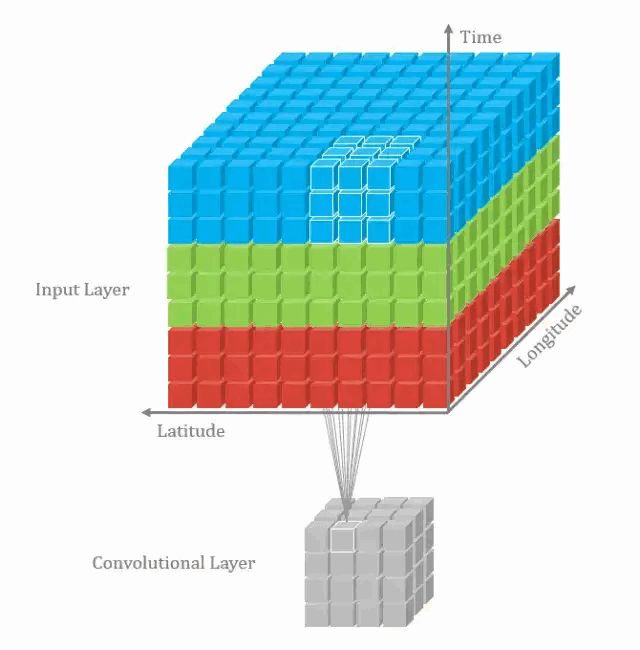
在上一个插图中,可以看出,这实际上是在完成3D-卷积。但通常意义上,仍然称之为深度学习的2D-卷积。因为filters的深度和输入层的深度相同,3D-filters仅在2个维度上移动(图像的高度和宽度),得到的结果为单通道。通过将2D-卷积的推广,在3D-卷积定义为filters的深度小于输入层的深度(即卷积核的个数小于输入层通道数),故3D-filters需要在三个维度上滑动(输入层的长、宽、高)。在filters上滑动的每个位置执行一次卷积操作,得到一个数值。当filters滑过整个3D空间,输出的结构也是3D的。2D-卷积和3D-卷积的主要区别为filters滑动的空间维度,3D-卷积的优势在于描述3D空间中的对象关系。3D关系在某一些应用中十分重要,如3D-对象的分割以及医学图像的重构等。
对于1*1卷积而言,表面上好像只是feature maps中的每个值乘了一个数,但实际上不仅仅如此,首先由于会经过激活层,所以实际上是进行了非线性映射,其次就是可以改变feature maps的channel数目。
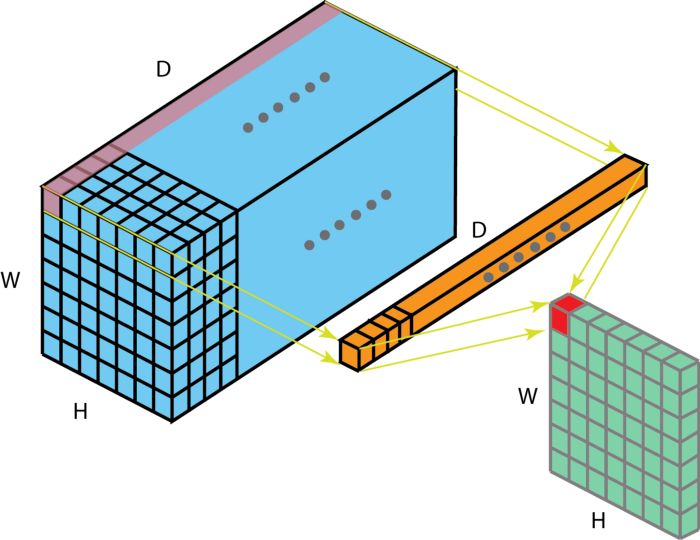
上图中描述了:在一个维度为 H x W x D 的输入层上的操作方式。经过大小为 1 x 1 x D 的filters的 1 x 1 卷积,输出通道的维度为 H x W x 1。如果我们执行 N 次这样的 1 x 1 卷积,然后将这些结果结合起来,我们能得到一个维度为 H x W x N 的输出层。
空间可分离卷积