
目前使用得最多的deconvolution有2种:
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
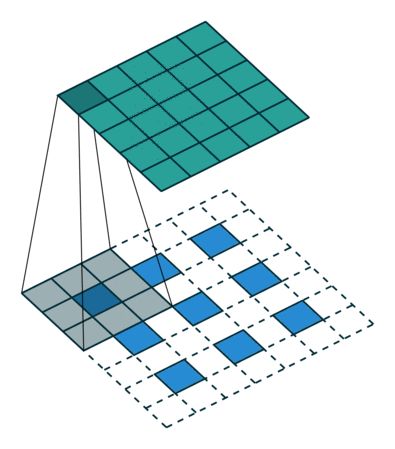
方法2:记录pooling index,然后扩大空间,再用卷积填充。图像的deconvolution过程如下:
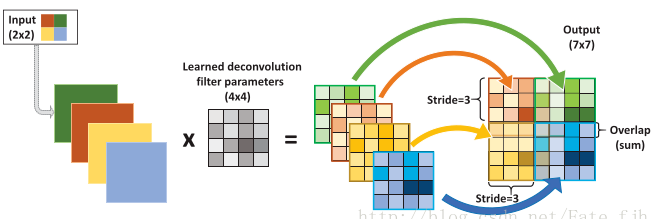
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出反卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
论文:Involution: Inverting the Inherence of Convolution for Visual Recognition (CVPR'21)
代码开源地址:https://github.com/d-li14/involution
尽管神经网络体系结构发展迅速,但卷积仍然是深度神经网络架构构建的主要组件。从经典的图像滤波方法中得到的灵感,卷积核具有2个显著的特性Spatial-agnostic和Channel-specific。在Spatial上,前者的性质保证了卷积核在不同位置之间的共享,实现了平移不变性。在Channel域中,卷积核的频谱负责收集编码在不同Channel中的不同信息,满足后一种特性。此外,自从VGGNet出现以来,现代神经网络通过限制卷积核的空间跨度不超过3*3来满足卷积核的紧凑性。
一方面,尽管Spatial-Agnostic和Spatial-Compact的性质在提高效率和解释平移不变性等价方面有意义,但它剥夺了卷积核适应不同空间位置的不同视觉模式的能力。此外,局部性限制了卷积的感受野,对小目标或者模糊图像构成了挑战。另一方面,众所周知,卷积核内部的通道间冗余在许多经典深度神经网络中都很突出,这使得卷积核对于不同通道的灵活性受到限制。
为了克服上述限制,本文作者提出了被称为involution的操作,与标准卷积相比,involution具有对称反向特性,即Spatial-Specific和Channel-Agnostic。具体地说,involution核在空间范围上是不同的,但在通道上是共享的。由于involution核的空间特性,如果将其参数化为卷积核等固定大小的矩阵,并使用反向传播算法进行更新,则会阻碍学习到的对合核在不同分辨率的输入图像之间的传输。在处理可变特征分辨率的最后,属于特定空间位置的involution核可能仅在对应位置本身的传入特征向量的条件下作为实例生成。此外,作者还通过在通道维数上共享involution核来减少核的冗余。
综合上述2个因素,involution运算的计算复杂度随特征通道数量线性增加,动态参数化involution核在空间维度上具有广泛的覆盖。通过逆向设计方案,本文提出的involution具有卷积的双重优势:
1:involution可以在更广阔的空间中聚合上下文,从而克服了对远程交互进行建模的困难
2:involution可以在不同位置上自适应地分配权重,从而对空间域中信息最丰富的视觉元素进行优先排序。
大家也都知道最近基于Self-Attention进一步的研究表明,很多任务为了捕获特征的长期依赖关系提出使用Transformer来进行建模。在这些研究中,纯粹的Self-Attention可以被用来构建具有良好性能的独立模型。而本文将揭示Self-Attention是通过一个复杂的关于核结构的公式来对邻近像素之间的关系进行建模,其实也就是involution化的特殊情况。相比之下,本文所采用的核是根据单个像素生成的,而不是它与相邻像素的关系。更进一步,作者在实验中证明,即使使用简单版本,也可以实现Self-Attention的精确。
involution的计算过程如下图所示: