
设定一个相对误差 ,当该值超过一定的阈值时,则认为其是一个异常点,剔除这个异常点,将异常点剔除之 后。再计算平均误差来对模型进行评价。
使用误差的分位数来代替
如利用中位数来代替平均数。例如 MAPE:

MAPE是一个相对误差的中位数,当然也可以使用别的分位数。
2、分类(Classification)算法指标
准确率 Accuracy
混淆矩阵 Confusion Matrix
精确率(查准率) Precision
召回率(查全率)Recall
Fβ Score
AUC Area Under Curve
KS Kolmogorov-Smirnov
2.1 准确率 Acc预测正确的样本的占总样本的比例,取值范围为[0,1],取值越大,模型预测能力越好。
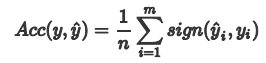
其中:
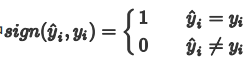
准确率评价指标对平等对待每个类别,即每一个样本判对 (0) 和判错 (1) 的代价都是一样的。
问题 6: 准确率有什么缺陷?什么时候准确率指标会失效?
对于有倾向性的问题,往往不能用准确率指标来衡量。
比如,判断空中的飞行物是导弹还是其他飞行物,很显然为了减少损失,我们更倾向于相信是导弹而采用相应的防护措施。此时判断为导弹实际上是其他飞行物与判断为其他飞行物实际上是导弹这两种情况的重要性是不一样的;
对于样本类别数量严重不均衡的情况,也不能用准确率指标来衡量。
比如银行客户样本中好客户990个,坏客户10个。如果一个模型直接把所有客户都判断为好客户,得到准确率为99%,但这显然是没有意义的。
对于以上两种情况,单纯根据Accuracy来衡量算法的优劣已经失效。这个时候就需要对目标变量的真实值和预测值做更深入的分析。
2.2 混淆矩阵 Confusion Matrix
这里牵扯到三个方面:真实值,预测值,预测值和真实值之间的关系,其中任意两个方面都可以确定第三个。
通常取预测值和真实值之间的关系、预测值对矩阵进行划分:
True positive (TP)
真实值为Positive,预测正确(预测值为Positive)
True negative (TN)
真实值为Negative,预测正确(预测值为Negative)
False positive (FP)
真实值为Negative,预测错误(预测值为Positive),第一类错误, Type I error。
False negative (FN)