
真实值为Positive,预测错误(预测值为 Negative),第二类错误, Type II error。
2.3 精确率(查准率) PrecisionPrecision 是分类器预测的正样本中预测正确的比例,取值范围为[0,1],取值越大,模型预测能力越好。
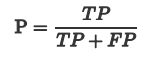
Recall 是分类器所预测正确的正样本占所有正样本的比例,取值范围为[0,1],取值越大,模型预测能力越好。
应用场景:
地震的预测 对于地震的预测,我们希望的是Recall非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺 牲Precision。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
“宁错拿一万,不放过一个”,分类阈值较低
嫌疑人定罪 基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。即使有时候放过了一些罪犯,但也 是值得的。因此我们希望有较高的Precision值,可以合理地牺牲Recall。
“宁放过一万,不错拿一个”,“疑罪从无”,分类阈值较高
问题 7: 某一家互联网金融公司风控部门的主要工作是利用机器模型抓取坏客户。互联网金融公司要扩大业务量,尽量多的吸引好客户,此时风控部门该怎样调整Recall和Precision?如果公司坏账扩大,公司缩紧业务,尽可能抓住更多的坏客户,此时风控部门该怎样调整Recall和Precision?
如果互联网公司要扩大业务量,为了减少好客户的误抓率,保证吸引更多的好客户,风控部门就会提高阈值,从而提高模型的查准率Precision,同时,导致查全率Recall下降。如果公司要缩紧业务,尽可能抓住更多的坏客户,风控部门就会降低阈值,从而提高模型的查全率Recall,但是这样会导致一部分好客户误抓,从而降低模型的查准率 Precision。
根据以上几个案,我们知道随着阈值的变化Recall和Precision往往会向着反方向变化,这种规律很难满足我们的期望,即Recall和Precision同时增大。
问题 8: 有没有什么方法权衡Recall和Precision 的矛盾?
我们可以用一个指标来统一Recall和Precision的矛盾,即利用Recall和Precision的加权调和平均值作为衡量标准。
2.5 Fβ ScorePrecision和Recall 是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下Precision高、Recall 就低, Recall 高、Precision就低。为了均衡两个指标,我们可以采用Precision和Recall的加权调和平均(weighted harmonic mean)来衡量,即Fβ Score,公式如下:
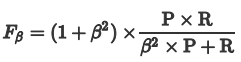
β表示权重:
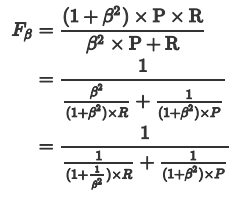
通俗的语言就是:β 越大,Recall的权重越大, 越小,Precision的权重越大。
由于Fβ Score 无法直观反映数据的情况,同时业务含义相对较弱,实际工作用到的不多。
2.6 ROC 和 AUCAUC是一种模型分类指标,且仅仅是二分类模型的评价指标。AUC是Area Under Curve的简称,那么Curve就是 ROC(Receiver Operating Characteristic),翻译为"接受者操作特性曲线"。也就是说ROC是一条曲线,AUC是 一个面积值。
2.6.1 ROC
ROC曲线为 FPR 与 TPR 之间的关系曲线,这个组合以 FPR 对 TPR,即是以代价 (costs) 对收益 (benefits),显然收益越高,代价越低,模型的性能就越好。