AUC更多的是关注对计算概率的排序,关注的是概率值的相对大小,与阈值和概率值的绝对大小没有关系 例子中并不关注小明是不是成人,而关注的是,预测为成人的概率的排序。
AUC只关注正负样本之间的排序,并不关心正样本内部,或者负样本内部的排序。这也体现了AUC的本质: 任意个正样本的概率都大于负样本的概率的能力。
例子中AUC只需要保证(小明和姐姐)(爸爸和妈妈),小明和姐姐在前2个排序,爸爸和妈妈在后2个排序,而不会考虑小明和姐姐谁在前,或者爸爸和妈妈谁在前 。AUC只与概率的相对大小(概率排序)有关,和绝对大小没关系。由于三个模型概率排序的前两位都是未成年人(小明,姐姐),后两位都是成年人(妈妈,爸爸),因此三个模型的AUC都等于1。
问题 14:以下已经对分类器输出概率从小到大进行了排列,哪些情况的AUC等于1, 情况的AUC为0(其中背景色表示True value,红色表示成年人,蓝色表示未成年人)。

D 模型, E模型和F模型的AUC值为1,C 模型的AUC值为0(爸妈为成年人的概率小于小明和姐姐,显然这个模型预测反了)。
AUC的计算
法1:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积(曲线)之和。计算的准确率与阈值的准确率有关 。
法2:根据AUC的物理意义,我们计算正样本预测结果大于负样本预测结果的概率。取n1* n0(n1为正样本数,n0为负样本数)个二元组,每个二元组比较正样本和负样本的预测结果,正样本预测结果高于负样本预测结果则为预测正确,预测正确的二元组占总二元组的比率就是最后得到的AUC。时间复杂度为O(N* M)。
法3:我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n (n=n0+n1,其中n0为负样本个数,n1为正样本个数),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有n1-1个其他正样本比他score小,那么就有(rank_max-1)-(n1-1)个负样本比他score小。其次为(rank_second-1)-(n1-2)。最后我们得到正样本大于负样本的概率为 :
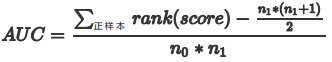
其计算复杂度为O(N+M)。
下面有一个简单的例子:
真实标签为 (1, 0, 0, 1, 0) 预测结果1(0.9, 0.3, 0.2, 0.7, 0.5) 预测结果2(0.9, 0.3, 0.2, 0.7, 0.8))
分别对两个预测结果进行排序,并提取他们的序号 结果1 (5, 2, 1, 4, 3) 结果2 (5, 2, 1, 3, 4)
对正分类序号累加 结果1:SUM正样本(rank(score))=5+4=9 结果2: SUM正样本(rank(score))=5+3=8
计算两个结果的AUC: 结果1:AUC= (9-2*3/2)/6=1 结果2:AUC= (8-2*3/2)/6=0.833
问题 15:为什么说 ROC 和AUC都能应用于非均衡的分类问题?
ROC曲线只与横坐标 (FPR) 和 纵坐标 (TPR) 有关系 。我们可以发现TPR只是正样本中预测正确的概率,而FPR只是负样本中预测错误的概率,和正负样本的比例没有关系。因此 ROC 的值与实际的正负样本比例无关,因此既可以用于均衡问题,也可以用于非均衡问题。而 AUC 的几何意义为ROC曲线下的面积,因此也和实际的正负样本比例无关。
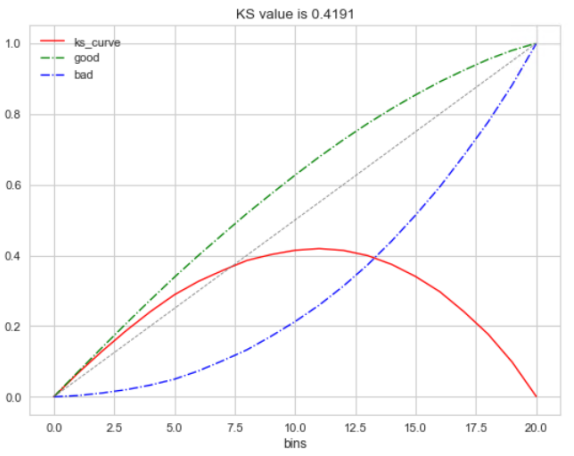
2.7 KS Kolmogorov-SmirnovKS值是在模型中用于区分预测正负样本分隔程度的评价指标,一般应用于金融风控领域。
与ROC曲线相似,ROC是以FPR作为横坐标,TPR作为纵坐标,通过改变不同阈值,从而得到ROC曲线。
而在KS曲线中,则是以阈值作为横坐标,以FPR和TPR作为纵坐标,ks曲线则为TPR-FPR,ks曲线的最大值通常为ks值。
为什么这样求KS值呢?我们知道,当阈值减小时,TPR和FPR会同时减小,当阈值增大时,TPR和FPR会同时增大。而在实际工程中,我们希望TPR更大一些,FPR更小一些,即TPR-FPR越大越好,即ks值越大越好。
可以理解TPR是收益,FPR是代价,ks值是收益最大。图中绿色线是TPR、蓝色线是FPR。